
Semantic Web Architecture
The architecture of semantic web is illustrated in the figure below. The first layer, URI and Unicode,
follows the important features of the existing WWW. Unicode is a standard of
encoding international character sets and it allows that all human languages
can be used (written and read) on the web using one standardized form. Uniform Resource
Identifier (URI) is a string of a standardized form that allows to uniquely
identify resources (e.g., documents). A subset of URI is Uniform Resource
Locator (URL), which contains access mechanism and a (network) location of a
document - such as http://www.example.org/. Another subset of URI
is URN that allows to identify a resource without implying its location and
means of dereferencing it - an example is urn:isbn:0-123-45678-9.
The usage of URI is important for a distributed internet system as it provides
understandable identification of all resources. An international variant to URI
is Internationalized Resource Identifier (IRI) that allows usage of Unicode
characters in identifier and for which a mapping to URI is defined. In the rest
of this text, whenever URI is used, IRI can be used as well as a more general
concept.
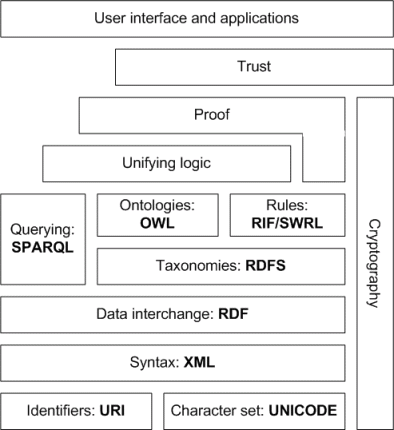
Semantic web architecture in layers
Extensible Markup Language (XML) layer with XML namespace and XML schema definitions makes sure that there is a common syntax used in the semantic web. XML is a general purpose markup language for documents containing structured information. A XML document contains elements that can be nested and that may have attributes and content. XML namespaces allow to specify different markup vocabularies in one XML document. XML schema serves for expressing schema of a particular set of XML documents.
A core data representation format for semantic web is Resource Description Framework (RDF). RDF is a framework for representing information about resources in a graph form. It was primarily intended for representing metadata about WWW resources, such as the title, author, and modification date of a Web page, but it can be used for storing any other data. It is based on triples subject-predicate-object that form graph of data. All data in the semantic web use RDF as the primary representation language. The normative syntax for serializing RDF is XML in the RDF/XML form. Formal semantics of RDF is defined as well.
RDF itself serves as a description of a graph formed by triples. Anyone can define vocabulary of terms used for more detailed description. To allow standardized description of taxonomies and other ontological constructs, a RDF Schema (RDFS) was created together with its formal semantics within RDF. RDFS can be used to describe taxonomies of classes and properties and use them to create lightweight ontologies.
More detailed ontologies can be created with Web Ontology Language OWL. The OWL is a language derived from description logics, and offers more constructs over RDFS. It is syntactically embedded into RDF, so like RDFS, it provides additional standardized vocabulary. OWL comes in three species - OWL Lite for taxonomies and simple constrains, OWL DL for full description logic support, and OWL Full for maximum expressiveness and syntactic freedom of RDF. Since OWL is based on description logic, it is not surprising that a formal semantics is defined for this language.
RDFS and OWL have semantics defined and this semantics can be used for reasoning within ontologies and knowledge bases described using these languages. To provide rules beyond the constructs available from these languages, rule languages are being standardized for the semantic web as well. Two standards are emerging - RIF and SWRL.
For querying RDF data as well as RDFS and OWL ontologies with knowledge bases, a Simple Protocol and RDF Query Language (SPARQL) is available. SPARQL is SQL-like language, but uses RDF triples and resources for both matching part of the query and for returning results of the query. Since both RDFS and OWL are built on RDF, SPARQL can be used for querying ontologies and knowledge bases directly as well. Note that SPARQL is not only query language, it is also a protocol for accessing RDF data.
It is expected that all the semantics and rules will be executed at the layers below Proof and the result will be used to prove deductions. Formal proof together with trusted inputs for the proof will mean that the results can be trusted, which is shown in the top layer of the figure above. For reliable inputs, cryptography means are to be used, such as digital signatures for verification of the origin of the sources. On top of these layers, application with user interface can be built.
In the rest of this chapter, we will describe some of these technologies - RDF, RDFS, OWL, and SPARQL.
(c) Marek Obitko, 2007 - Terms of use